1
 作者您好,请问hyp.scratch这4个yaml文件有什么区别?各自在什么样的情况下使用?程序应该在哪里选择使用哪个hyp.scratch文件呢?另外,标注红色方框的这两个yaml 文件还有什么区别?
作者您好,请问hyp.scratch这4个yaml文件有什么区别?各自在什么样的情况下使用?程序应该在哪里选择使用哪个hyp.scratch文件呢?另外,标注红色方框的这两个yaml 文件还有什么区别?
作者您好,请问hyp.scratch这4个yaml文件有什么区别?各自在什么样的情况下使用?程序应该在哪里选择使用哪个hyp.scratch文件呢?另外,标注红色方框的这两个yaml 文件还有什么区别?
你的教程,我感觉写的比较笼统和广泛,一些关于参数/文件的含义以及如何配置的详细问题,我应该在哪里寻找答案?您有整理或总结过相关问题吗?谢谢
@Wanghe1997 hyp文件在训练期间指定,即python train.py --hyp hyp.scratch.yaml
https://github.com/ultralytics/yolov5/blob/c2523be634a94da2b1b2a43c11b25827a0de990d/train.py#L445
感谢你。Q1:scratch:default是否意味着所有尺寸的模型都可以尝试?为什么小模型要设置小的初始学习率?Q2:对于小模型(v5n,v5s),训练过程中batch-size设置小(8,16)好还是大(32,64,128)好?批量大小设置有什么技巧或参数吗?
@Wanghe1997 批量大小应设置得尽可能大,以充分利用 GPU。
自动批处理您可以使用YOLOv5 AutoBatch(新)通过传递 来找到最适合您的训练的批量大小--batch-size -1。根据您的训练设置,AutoBatch 将求解 90% 的 CUDA 内存利用率批量大小。AutoBatch 是实验性的,仅适用于单 GPU 训练。它可能不适用于所有系统,并且不建议用于生产用途。
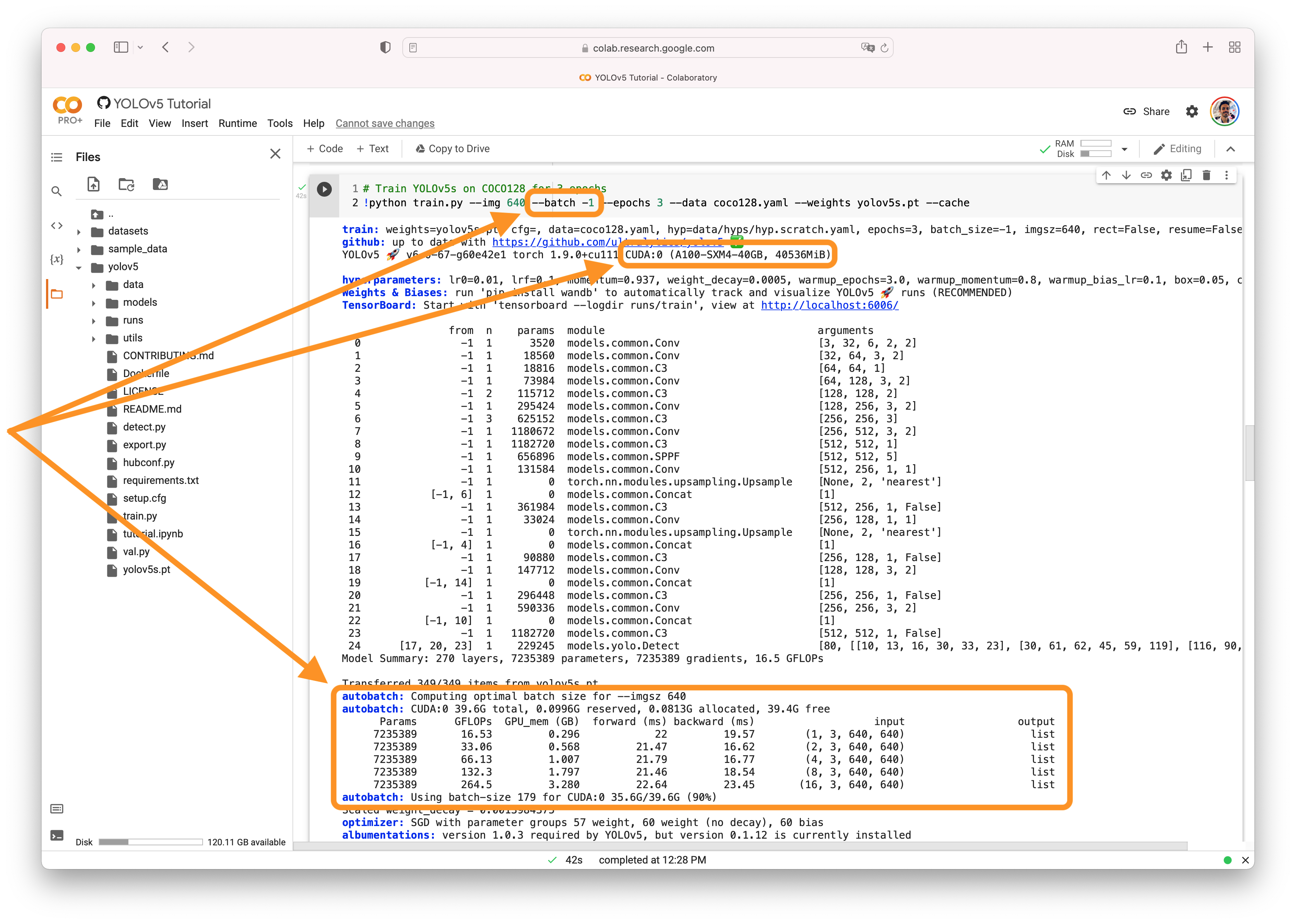
祝您好运,如果您有任何其他问题,请告诉我们!
@Wanghe1997 是的
那么只要在train.py中将batch-size设置为1,程序就会自动执行AutoBatch吗?除此之外不需要做任何配置吗?
@Wanghe1997 不,截图显示-1,而不是1
好,谢谢
我刚刚用我的数据集测试了 AutoBatch,测得的最佳批量大小是 111。但是,我使用 111 这个值来训练 yolov5s,它提示错误:无法找到有效的 cuDNN 算法来运行卷积。我感觉Autobatch测试不准确!虽然我的显卡是RTX3090,24G显存,但是理论上无法承受这么大的batch size
@Wanghe1997 感谢您的反馈。如上所述:

不客气。我的系统是windows10,正好用RTX3090单卡进行测试。看来 AutoBatch 还不太准确。或者只能针对coco128进行计算,而不能针对自定义数据集进行计算?
@Wanghe1997 数据集并不重要。它仅在具有 K80、T4、P100、V100、A100 的 Colab 实例上进行了评估,因此还没有消费者卡。